简介: 入门级别讲解,分析多线程竞争同一共享资源,运行结果不符预期的原因;故书一简例,讲解何谓 非线程安全 ?以及使用 atomic 和 mutex 来解决此缺陷场景,最终 线程安全 获得预期结果。
[TOC]
本文初发于 “偕臧的小站“,同步转载于此。
受众
有基本的多线程理论知识,但未曾深入研究 “运行不符预期结果” 的萌新?亦或对多线程未曾了解,道听途说、知识点模糊,实际不甚理解原理的读者。都是本文的最佳读者。若已早熟练和精通于多线程项目,可直接关闭本文,珍惜时间,可以用来干点其它的什么,摸个🐟,喝杯肥宅快乐水(加冰)。
场景
在 win10 21H1 📎 Visual Studio 2019 的环境中,写了一个最简单的多线程例子,下面来分析一波:
#include <thread>
#include <iostream>
using namespace std;
int g_num = 0;
void addition()
{
for (int i = 0; i < 5000; ++i) {
g_num++;
}
}
int main()
{
thread th1(addition);
thread th2(addition);
th1.join();
th2.join();
cout << "g_num:" << g_num << endl;
return 0;
}同时起两个线程 th1,th2;不做任何限制;对同一全局变量 g_num 进行写增加操作;预期 运行结果一定为 10000。理由为 即使是两个线程经过 CPU 时间片轮转、互相争夺此 g_num 变量的写增加;但是总的是次数来看,Line 7-12 即使互相咬合交替执行(线程竞争),但最终此函数 addition()(此段代码片)都一定被运行了 5000 + 5000 = 10000 次;并且此处只有一行自增代码,是不应该会有问题的。
实际运行结果 为:有时候能数据为 10000, 有时候低于 10000,两者概率都很大。和预期的不符合,被打脸了😰;
故疯狂吐槽 CPU 不讲武德,明明代码片会运行 10000 次,但是最终结果经常不符合预期(偶尔会符合预期),完全不可控。此被称为 线程不安全,出现了多线程竞争情况,导致结果未能符合预期。
造成差异的 根因分析 :
即使是仅一行 g_num++; 代码,也属于高级语言,被编译器翻译为汇编(低级语言)后,是被解释为多行汇编语言执行的; 而 CPU 每次执行的最小单位可看作是一条精简的指令(此处姑且理解为一行汇编代码)。你以为只执行一行代码 C++ 代码,实际则是执行三行汇编代码。此属于非原子操作、或非最小执行单位的机器指令。此时多线程切换出去,某种巧合情况下会得出错误结果(下文有详细分析)。
分析
以上也仅仅是揣测,下面一块看实锤。在 VS 2019 中 Line 9: g_num++; 处行打上 F9 断点,Debug 模式下 F5 调试卡住此行,右键菜单选中 “转到反汇编(T) ”,可看到如下代码片,进行 C++ 的对应的汇编分析。
g_num++;
00C310EF mov ecx,dword ptr [g_num (0C353F8h)] // 将 g_num 的内容写入到 ecx
00C310F5 add ecx,1 // 计数器 ecx 数值加 1
00C310F8 mov dword ptr [g_num (0C353F8h)],ecx // 将 ecx 的内容写入到 g_num 中此三行汇编分析至此,只能说真的已到了最底层,无法再往下给你刨更底层了( 01010101 二进制可不算)。
汇编语言储备:
- mov 指令:据传送指令,用于将一个数据从源地址传送到目标地址(寄存器间的数据传送本质上也是一样的)。其特点是不破坏源地址单元的内容。
- add 指令: 加法指令, 两数相加。
- ecx:计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
结合代码分析多线程运行:
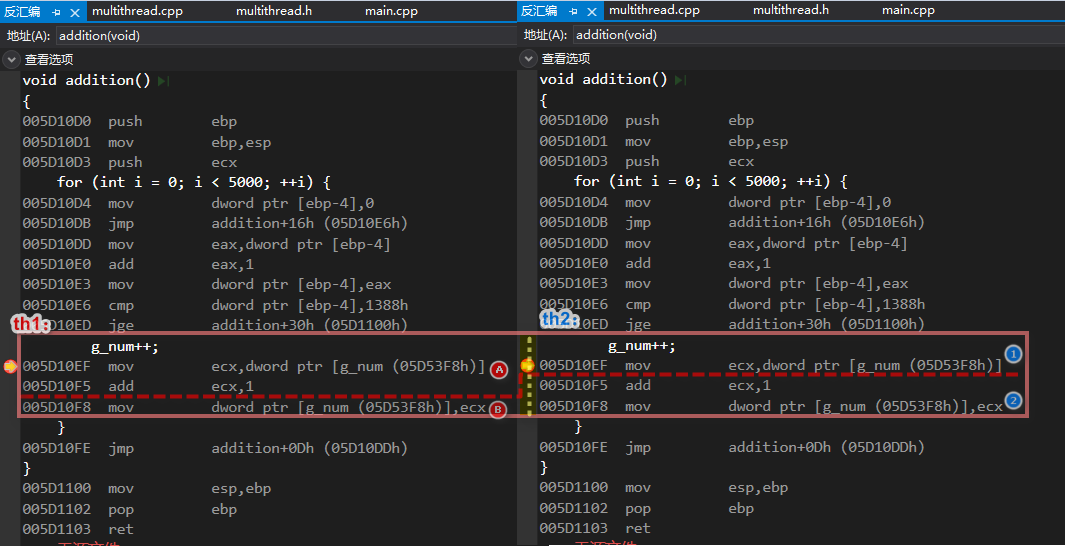
对于出现多线程竞争情况,实际运行结果为 5000 多,化抽象为一具体理解。每次执行 g_num++; 三行汇编代码时,线程 th1 、th2 每次都按照如下循序交替运行;
- 【1步骤】th1: A
- 【2步骤】th2: ①
- 【3步骤】th1: B
- 【4步骤】th2: ②
按照此顺序来模拟执行一遍,每一步骤结果如下:
| // 第一次进来 g_num = 0 | ecx的值 | ptr[g_num (0C353F8h)]的数值 | |
|---|---|---|---|
| 执行【1步骤】th1: A | 0 | 0 | |
| 1 | 0 | ||
| 执行【2步骤】th2: ① | 0(非希望的结果,线程竞争错误根因) | 0( 此时未被改变) | |
| 执行【3步骤】th1: B | 0 | 0 | |
| 执行【4步骤】th2: ② | 1 | 0 | |
| 1 | 1(虽共运行两次加1,可最终结果却为1) |
可发现,线程 th1 和 th2 各自交替 的执行一遍完整的 addition() 函数后,共执行了两遍对 g_num++ 的操作,但是其结果只会增加一遍。每次按照此顺序线程交替歌执行 5000 次后,最终的结果就是 5000。但实际总有那么几次是被 th1 执行完成了后,才切换到 th2 执行,故而实际运行结果为 5000出点头左右;也算是印证了无限制的多线程竞争读写同一资源,会出现不符合预期的情况。
解决
问题产生了,那么我们应该如何修正、或避免此情况呢?实际的解决的方式就有很多种了,这里提两种方案,最终代码如下
- 定义为 原子变量操作 atomic ;
- 对多线程访问的共享资源进行加锁 mutex
#include <atomic>
#include <mutex>
#include <thread>
#include <iostream>
using namespace std;
// 方案一:定义为原子变量 atomic
//atomic<int> g_num = 0;
// 方案二:加锁 mutex
int g_num = 0;
mutex g_mutex;
void addition()
{
for (int i = 0; i < 5000; ++i) {
g_mutex.lock();
g_num++;
g_mutex.unlock();
}
}
int main()
{
thread th1(addition);
thread th2(addition);
th1.join();
th2.join();
cout << "g_num:" << g_num << endl;
return 0;
}方案一(atomic)
如果每次能够将 g_num++; 的三行汇编捆绑打包,执行完这一坨之后, CPU 才会切到其它线程,那么此问题便迎刃而解。巧了;前辈们早提供工具实现此愿望 – 原子操作 atomic;
只需要修改一行代码即可,即可保证此自增代码一定是原子操作的。
// atomic
atomic<int> g_num = 0; // 替换 int g_num = 0; 再看一眼汇编也发生了变化,从而确保了此行对 g_num 的自增一定是原子操作级别的(姑且理解为:此原子行为不可再分割多个步骤;或 CPU 一定是运行此捆绑的几行后,才会切给其它线程);

无论运行多少次,此结果一定是符合预期的 10000;此也被称作为 线程安全 。和使用单线程运行和结果是一致的。
方案二(mutex)
在 g_num++; 的上面使用同一把互斥锁 mutex g_mutex; 对共享资源进行加锁和解锁,确保共享全局变量的写操作,每次仅 只能有一个线程对其写操作,使用期间其它线程不能对此写操作,若其它线程代码执行到加锁处,则变更为等待状态;只有被当前线程使用完毕解锁后,其它线程才可以去加锁,进行数值修改,修改完成后也会对应的解锁。如此循环往复。最终也是得到符合预期的结果,加锁后也属于 线程安全 的。加锁的原理 对应现实生活,就是多人上厕所,先进去的把厕所门关了,后来的人只能门外等着,上一个人用完后开门后,其他人才能进去;循环往复(就像历史总是循环交替一样)。
// 加锁 mutex
int g_num = 0;
mutex g_mutex;
void addition()
{
for (int i = 0; i < 5000; ++i) {
g_mutex.lock();
g_num++;
g_mutex.unlock();
}
}额外探索
使用加锁的目的和预期我们已经达到了,但是可以再更进一步探索;故意写一行 cout << 打印语句,再执行加锁;
// mutex
int g_num = 0;
mutex g_mutex;
void addition()
{
for (int i = 0; i < 5000; ++i) {
cout << "threadId:" << this_thread::get_id() << " g_num:" << g_num << endl;
g_mutex.lock(); // 尝试和上一行的 cout 行互换位置
g_num++;
g_mutex.unlock();
}
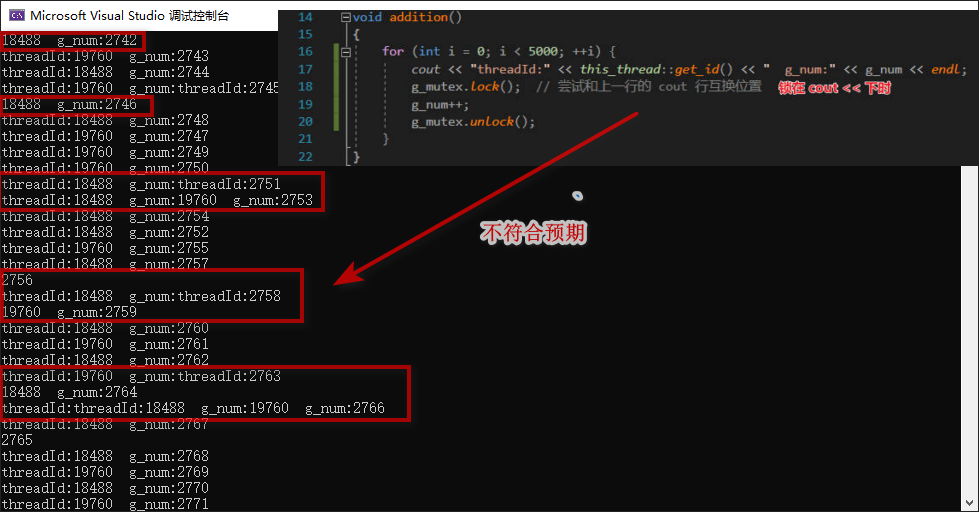
}发现 g_num 的最终结果 总 是符合预期的,但是 cout << 输出语句出现了错乱!!! 是不是有一种时曾相识的感觉,甚是眼熟;你看像不像“这一行被翻译为了多行汇编指令,但是这一推汇编指令还没执行完毕,就被 CPU 通过时间片轮转,切换到其他线程了。” ???
cout<< 的底层是会调用系统级的输出函数的,此时会由用户态切换为内核态;且打印语句一般也耗时(相对),结合两者情况,是很容易出现下图的此情况的,输出语句被交替执行。
而将 g_mutex.lock(); 和 cout << xxx 行互换时,运行的结果每一行都是符合预期的。运行结果全是这种,整整齐齐的:
threadId:21496 g_num:9994
threadId:21496 g_num:9995
threadId:21496 g_num:9996
threadId:21496 g_num:9997
threadId:21496 g_num:9998
threadId:21496 g_num:9999
g_num:10000源码
https://github.com/xmuli/QtExamples【ExThreadSafety】
提示
若是自己写例子的话,推荐在 for 循环中 的次数写大一点;加写一句 printf() 或 cout<< 输出,都是很容易得到线程不安全的运行结果。另外若是写在 main() 中,则用 th1.join(); 函数,用来阻塞等待线程退出,获取线程退出的状态;而在类或者函数中,则使用 .detach() 来设置设置线程分离的属性。关于差异差异可参考 此文 。


